Overfitting and Underfitting.
Overfitting.
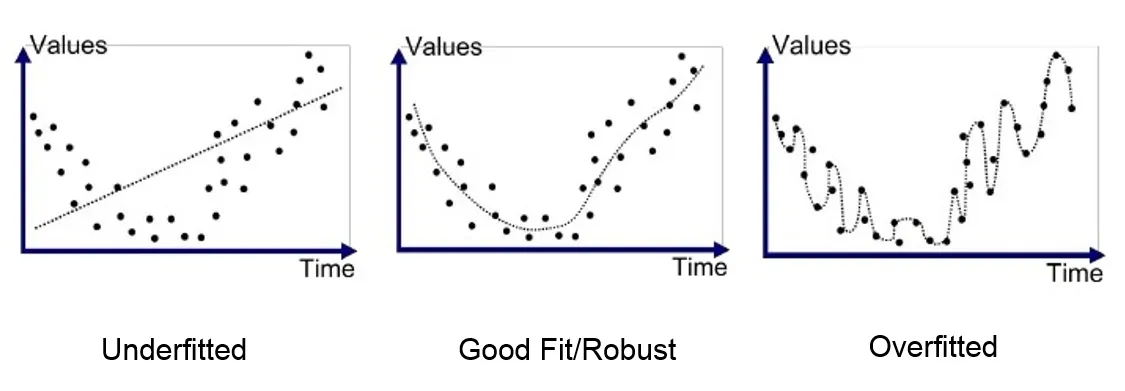
Overfitting occurs when a model has more errors in test data when compared to train data errors, i.e. when the model is too complex the training error is small while the test error is large. We can the overfitting based on the training dataset given and the test data. It can be identified by checking the validation metrics like the accuracy of the dataset and loss. In case of overfitting, the model accuracy is high for the data used in the training set and accuracy drops significantly on new datasets. If the validation metrics is bad compared to training metrics then the model is overfitting. The model fails to generalize and predict the accuracy of new data.
The reason for overfitting,
- The Main reason for overfitting is that we have small dataset, and model tries to learn from it. It fails when there is large set of data.
- Model learns the detail and noise in the training data to the extent that it negatively impacts the performance of the model on new data.
- High model complexity.
- Data used for training is not cleaned.
Reduce overfitting,
- We can reduce the overfitting by adding more data. Larger the dataset, model has more opportunity to learn from it. example, if the model is trained for 1,2,3,4 numbers it fails to recognize 5(new data), so we add more data to diversify the model so that it can predict the new data.
- Use Data Augmentation, one of the best solutions when we have limited data. It adds more modified data to the dataset similar to the existing data, so it not same as currently available.
- Reduce the complexity of the model.
- Regularization, Ridge(L2) regularization or Lasso(L1) regularization.

Underfitting.
When the model is too simple, both train and test errors are large. The data is too simple it fails to accurately catch relationships between a data features and target variable. Underfitting model often gives wrong output on the new data. If the accuracy is bad for both training data and test data, then the model is underfitting.
Reasons for underfitting.
- Data used for underfitting is not clean.
- Size of the dataset is not large enough.
- Model is too simple.
Reduce underfitting.
- Increase the complexity of model.
- Increase the number of epochs.
- Train the model with large datasets.
- Process the data and clean it before applying the model.
Good Fit.
When a model makes the prediction with zero errors then it is a good fit with highest accuracy.
Checking overfitting and underfitting over a given data.
import the libraries.

Get the X values,

random, generates 20 uniform random numbers for x variable between 0 and 1.
Similarly generate 20 normal distributed values for N.

using np.random.seed() will prevent data from changing due random every time we run the model.
Generate 20 values for Y, using the function, y = sin(2*pi*X) + 0.1 * N

Divide the data into two sets, training data and test data,




the data looks like,

Regression model is used to predict the continuous values. When there is huge amount of data it is difficult to manually look at the data and identify the pattern, analyze how the data is working. Regression model helps us in such scenarios, when we have large number of data and to make some kind of predictions.
Types of Regression.
- Simple Linear Regression
- Polynomial Regression
- Support vector Regression
- Decision Tree Regression
- Random Forest Regression
Apply polynomial regression,

polynomial regression is a form of regression analysis in which the relationship between the independent variable x and the dependent variable y is modelled as an nth degree polynomial in x.

when the polynomial degree is zero

It is a linear model with the curve that is quadratic rather straight line. Scikit-Learn provides PolynomialFeatures class to transform the features.
when polynomial degree is one


when polynomial degree is three,


when polynomial degree is nine


polynomial regression coefficients,

Train error vs Test error

Generate 100 more data points, when we try to run the model on the large data it best fits and avoids overfitting.

Regularization.
overfitting happens when model learns signal as well as noise in the training data and wouldn’t perform well on new data on which model wasn’t trained. It also occurs when the model is complex.
we can regularize the data to avoid overfitting.
- L1 regularization, Lasso regularization.
- L2 regularization, Ridge regularization.
Ridge regression is a model tuning method, it performs L2 regularization. it adds square of the magnitude of coefficient as to the loss function.

when the lambda value is large, it adds more weights and leads to under-fitting.
According to the sklearn cheat-sheet, ridge regression is useful in solving problems where you have less than one hundred thousand samples or when you have more parameters than samples. Ridge regression is almost identical to linear regression (sum of squares) except we introduce a small amount of bias. In return, we get a significant drop in variance. In other words, by starting with a slightly worse fit, Ridge Regression can provide better long term predictions.
The bias added to the model is also known as the Ridge Regression penalty. We compute it by multiplying lambda by the squared weight of each individual feature.
chart for various lambda values.

when the lambda value is less it best fits the data, reduce the errors and gives better results.
Reference,
- https://medium.com/@corymaklin/machine-learning-algorithms-part-11-ridge-regression-7d5861c2bc76
- https://mintu07ruet.github.io/files/2001.html
- google scholar articles and white papers.
